들어가며...
시작에 앞서 현재 포스팅은 7.13.X 버전을 기준으로 작성됩니다. (현재 ES 버전은 7.15.x)
엘라스틱이 아무래도 버전 업데이트가 빠른 편이다 보니 공식 Document가 아닌 블로그 글 등을 읽을 때는
해당 글의 작성일자나 기준이 되는 버전을 먼저 확인하는 것을 추천한다.
추가적으로 잘못된 내용에 대한 지적은 언제나 환영합니다.
오늘의 주제
오늘은 엘라스틱 서치 내에서 클러스터 다음으로 큰 덩어리인
"노드"에 대해 이야기해보려고 한다.
이미 앞선 포스팅에서 여러 번 언급되기도 했고
클러스터에 대한 이해가 있는 분들이라면
전혀 어렵지 않은 내용이니 재미있게..? 읽을 수 있게 써보려 한다!
엘라스틱 서치 구성요소
가장 먼저 빼놓을 수 없는 복습 아닌 복습
엘라스틱은 다음과 같은 구성요소들을 포함하고 있고

오늘은 엘라스틱서치의 두 번째 이야기로 노드! 를 다뤄볼 예정이다.
그리고 오랜만에 짧은 분량의 글이 될 거 같다는 생각이 든다.
노드
노드는 ES 클러스터를 구성하는 각각의 ES 프로세스들을 의미한다.
일반적인 클러스터 구조에서 각각의 컴퓨터나 서버들이 노드 역할을 수행하는 것처럼
ES 클러스터에서는 각 ES 프로세스들이 클러스터를 구성하고 이를 "노드"라고 부른다.
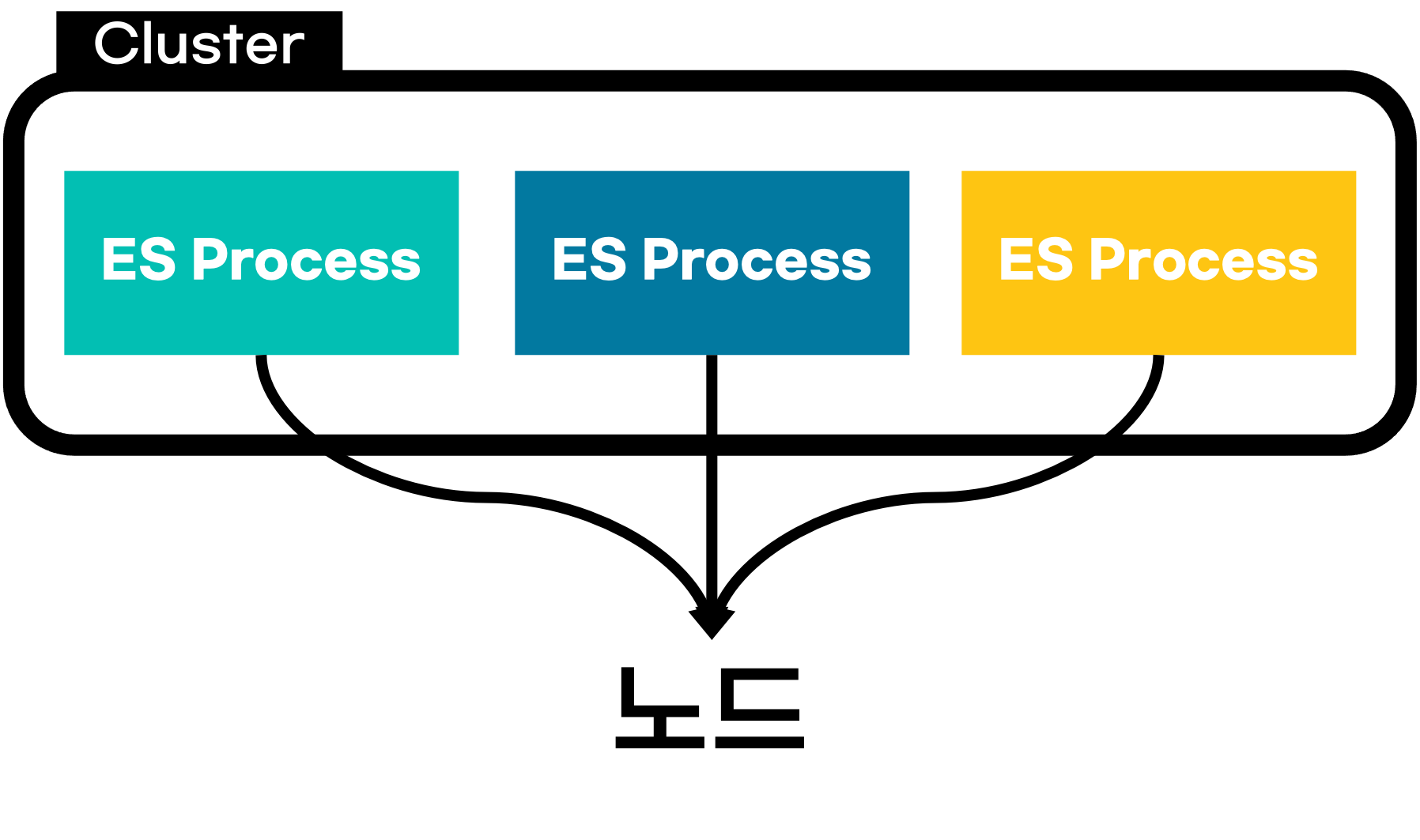
다시 정리하면 노드는
ES 클러스터를 구성하는 개별 서버로
데이터를 저장하고 클러스터의 색인화 및 검색을 가능하는 역할
각 노드는 고유한 name과 uuid를 가지고 있는데 이는 클러스터와 마찬가지로
노드를 식별하는 데 사용되는 요소로서 네트워크 내에 존재하는 특정 서버의 ES 프로세스가
현재 운영 중인 클러스터에서 어떤 역할을 담당하는지 식별한다.
결국 name과 uuid는 관리 목적에서 중요한 요소라고 볼 수 있다.
뒤에서도 나오겠지만 노드의 설정은 대부분 config 디렉터리 안의 yml 파일에서 가능한데
아래처럼 클러스터 이름을 명시해주어 해당 노드가 어느 클러스터의 일부를 구성하게 할지 지정이 가능하다.
# ---------------------------------- Cluster -----------------------------------
# Use a descriptive name for your cluster:
cluster.name: my_cluster
# ------------------------------------------------------------------------------
! 이때 주의해야 할게 하나 있는데 각 노드들이 아무리 같은 네트워크 상에 존재하더라도
서로 다른 클러스터 이름이 주어질 경우 다른 클러스터로 구성되게 된다.
! 근데 또 아무런 설정을 안 하면 기본적으로 "elasticsearch'라는 이름의 클러스터에
종속되기 때문에 테스팅이나 학습 목적에서는 클러스터 이름을 크게 신경 쓰지 않아도 된다..
노드 역할
클러스터를 구성하는 중요한 요소인 노드에는 name과 uuid를 제외하고도
한 가지 더 중요한 요소가 존재한다..
바로 "node role"이라고 불리는 노드의 역할이다.
기본적으로 노드는 각각 role이 존재하고 이 role에는
앞서 자주 나왔던 master, data을 비롯해 다양한 role들이 존재한다.
노드 역할 지정
노드의 role에 어떤 것들이 있고 각각에 대해
자세히 알아보기 전에 어떤 방식으로 노드의 역할을 명시하는지 알아보자!
1차적으로 config 디렉토리 안에 elasticsearch.yml 파일의 node 부분을 수정해
노드의 역할을 명시해줄 수 있고, 여기서 크게 두 가지 방법으로 나누어진다.
먼저 각각 필요한 모든 노드의 역할을 true, false 값을 주어 끄고 켜는 형태의 방법이 있다.
이 방법은 7.8 버전까지 사용되던 방식으로 현재도 동작하는 방식이긴 하다.
node.master: true
node.data: false
node.ingest: false
node.ml: false두 번째 방법은 배열의 형태로 해당 노드가 수행해야 하는 role을
작성해주는 방식이다. 이는 7.9 버전 이후로 현재까지 공식적으로 엘라스틱에서
소개하고 있는 방법으로 공식 document에서 확인 가능하다.
node.roles: [ master ]위처럼 두 가지 형태로 작성된 yml 파일의 일부는 모두 동일한 의미를 가지는데
다른 role은 수행하지 않고 오로지 master 노드로서의 역할만 수행하도록 작성된 yml 파일이다.
만일 아무런 역할도 명시하지 않은 경우에는 모든 role을 수행하는 노드로서 실행되게 된다.
이때 역할을 명시하지 않는 것과 역할을 명시하되 비워두는 것에 차이가 존재하는데
# case 1 - 아예 역할을 명시하지 않은 경우
# ------------------------------------ Node ------------------------------------
#
# ------------------------------------------------------------------------------
# case 2 - 역할을 명시하되 그 항목을 비워둔 경우
# ------------------------------------ Node ------------------------------------
node.roles: [ ]
#
# ------------------------------------------------------------------------------case 1의 경우 앞 서 말한 것처럼 모든 역할을 수행하는 노드가 실행되지만
case 2는 조금 다르게 "coordinate node"라고 불리는 실제 데이터 저장 및 요청을
수행하진 않지만, 전달과 결과만 취합하는 역할을 하는 코디네이트 role을 수행하게 된다.
자 그럼 본격적으로 어떤 role이 있고, 어떤 기능을 담당하는지 살펴보자!
Node Roles

엘라스틱 공식 다큐먼트에서 확인 가능한 role의 종류는 위와 같다.
이 외에도 앞서 나왔던 코디네이트 노드 등이 존재하는데 이번 글에서는
크게 maste, data, ingest, ml, transform, coordinate 정도로 크게 분류 지어 다뤄보려고 한다!
Master (Master - Eligible)
먼저 마스터, 마스터 후보 노드를 살펴보자!
마스터 노드는 클러스터 차원의 작업을 관리하는 역할로
인덱스 생성, 삭제 / 클러스터 내 노드 상태 감시 / 노드별로 할당될 샤드 결정 등
클러스터 내에서 일종의 "관리자" 역할을 수행한다.

위 이미지처럼 각 데이터 노드들로부터 상태 정보를 수집하고, 다시 재 전파해주는 대장이라고 이해하면 쉽다.
마스터 노드는 기본적으로 클러스터의 메타데이터를 저장하는 방식으로 클러스터의 상태 정보를 기억하는데
이때 메타 데이터는 클러스터가 재시작되는 경우에도 동일 상태를 유지하는 데 사용되는 중요한 요소이다.
그렇기에 데이터 노드와 마찬가지로 path.data 디렉토리 설정을 통해 메타 데이터 정보를 계속해서 관리하게 된다.
!! 클러스터 메타데이터는 데이터 노드에 저장된 데이터를 읽는 방법을 알려주는
일종의 설명서 역할을 하기 때문에 메타 데이터가 손실되면
데이터 노드에 저장된 데이터를 읽을 수 없는 불상사가 발생하기도 한다.
추가적으로 건강한 클러스터 상태를 유지하기 위해서는 안정적으로 유지되는 마스터 노드가 반드시 존재해야 한다.
이는 앞서 등장했던 스플릿 브레인 현상에서 다룬 내용과 유사하다고 보면 된다!
마스터 후보 노드 (Master - eligible)
다음으로 마스터 후보 노드는 마스터 역할을 수행할 수 있는 예비 마스터 노드의 개념으로
voting - only인 경우를 제외하면 어떤 마스터 후보 노드던 마스터 노드로 선출될 자격을 가지고
마스터 노드의 역할을 수행할 수 있다.
기본적으로 마스터 후보 노드는 마스터 노드가 관리하는 클러스터 메타 데이터를 "공유" 받는
형태이기 때문에 마스터 노드에 장애 발생 시 즉각 대체 가능한 구조이다.
다만 일반적인 상황에서는 단순히 메타데이터를 공유하는 상태이기 때문에 실질적인 마스터 역할은
실제 마스터 노드로 선출되어 작동 중인 마스터 노드만이 담당하게 된다.
Dedicated master - eligible node
단순히 해석하면 전용 마스터 노드 (?) 정도로 부를 수 있는데
간단히 말해 다른 역할을 동시에 수행하지 않고 오로지 마스터/마스터 후보로서의 role만
가지고 있는 노드를 의미한다.
# 마스터 role만 작성해 마스터 전용 노드로 생성해준다.
node.roles: [ master ]그럼 왜 굳이 굳이 마스터 역할만 하는 노드를 따로 만드는 법을 얘기하는 걸까?
클러스터의 안정적인 운영을 위해서 마스터 노드의 역할이 중요하다는 것은 이제 누구나 충분히 이해했을 것이라고 생각한다.
마스터 노드에 장애가 발생하면 데이터 유실이나 클러스터 운영 불가 등 심각한 상황에 처할 수도 있기 때문이다.
그리고 마스터 노드가 중요한 만큼 마스터 노드를 굴리는데 필요한 리소스 또한 충분히 확보해야 한다는 것은 누구나 동의할 것이다.
그렇기 때문에 다른 작업에 필요한 리소스를 확보하기 위해 마스터 역할을 수행 못하게 되는 불상사를 방지하기 위해
마스터 전용 노드를 따로 지정해주는 것이다.
다만 엘라스틱을 활용해서 실제 서비스를 운영하는 것이 아니거나 10개 미만의 노드로 구성된 클러스터 구조라면
마스터 전용 노드를 따로 지정하는 것이 오히려 자원 낭비일 가능성이 크다.
노드가 10개 미만이라면 데이터의 양도 그리 많지 않은 편인 데다 그 역할을 구분 짓느라
노드를 하나 더 실행시키는 것이 더 큰 낭비가 될 수 있기 때문이다.
하지만 클러스터 규모가 커지고 다루는 데이터의 양이 많아질수록 확실하게 역할을 구분 짓고
클러스터를 구축해야 한다는 것 또한 잊으면 안 된다!!!
Voting - only master - eligible node
이 노드는 이름부터 참 긴데 마스터 노드 선출을 위한 과정에 참여는 가능하지만
최종적으로 마스터 역할은 수행할 수 없는 마스터 후보 노드를 의미한다.
node.roles: [ data, master, voting_only ]아래는 마스터 후보 노드를 voting - only 노드로 지정함과 동시에 data 노드 역할을 수행하게끔 한 코드이다.
공식 다큐먼트에 따르면 이 노드가 아주 애매하고 복잡하고 긴 이름을 가지게 된 이유는
엘라스틱의 발전 과정 중에 불행하게도 이런 이름을 가지게 되었다고 말하고 있다...
정말 이상한 이름인 건 인정한다... 겁나 헷갈림..
그 외에도 "투표 전용 마스터 후보 노드"의 특징을 간단히 보면
- 실제 마스터 역할 X → 실제 마스터 노드보다 적은 heap과 CPU 스펙을 가질 수 있음
- 다른 node role도 수행 가능
-
node.roles: [ data, master, voting_only ]
-
- 오로지 투표 전용 마스터 후보 노드로서 작동하게만도 설정 가능
-
node.roles: [ master, voting_only ]
-
- 마스터 선출 과정에서 tie breaker로서의 역할 담당
참고로 voting - only는 오로지 마스터 role이 설정된 노드에만 추가가 가능하다!!
Data Node (Hot, Warm, Cold, Frozen)
데이터 노드는 사용자가 색인한 문서를 저장하고
검색 요청을 처리해 결과를 반환하는 역할을 수행하는 노드이다.
이때 색인된 문서는 샤드 단위로 각 데이터 노드에 분산 저장되고
데이터 노드에 의해 데이터에 대한 CRUD, 검색, 집계 연산 등을 수행할 수 있다.
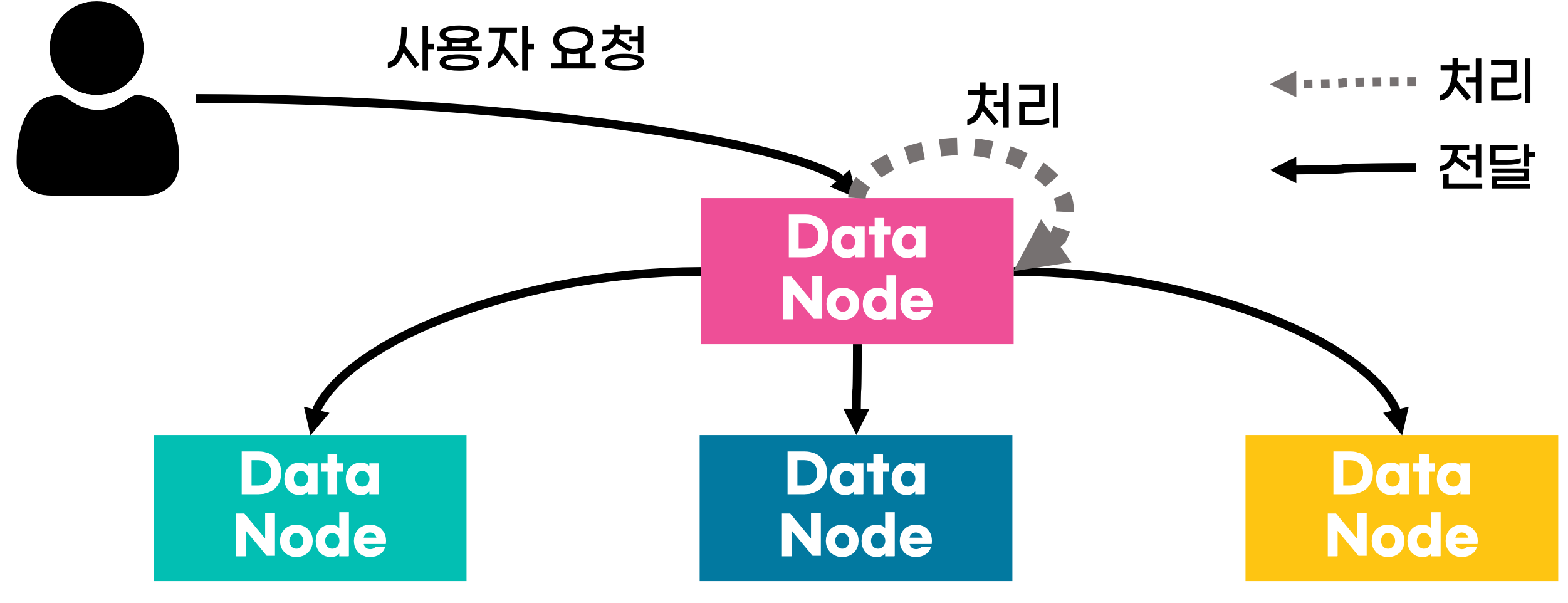
대부분의 요청은 요청을 받은 데이터 노드에서 처리하는 것이 일반적이지만
위 이미지처럼 다른 데이터 노드에 전달되어 처리하기도 하는데
이는 마스터 노드에게 전달받은 전체 클러스터의 상태 정보를 바탕으로 다른 노드에 업무를 분담하는 형태이다.
node.roles: [ data ]데이터 노드 또한 마스터와 마찬가지로 오직 "데이터" 노드 역할만 수행하도록 지정해줄 수 있는데
마스터 전용 노드와 동일하게 다른 role의 task에 방해받지 않을 수 있다는 이점을 가지게 된다.
muti - tier architecture의 경우 좀 더 세분화된 데이터 노드를 지정해서 tier 별로 적용시킬 수 있다.
이때 사용되는 role들이 바로 "data_content", "data_hot", "data_warm", "data_cold", "data_frozen" 등인데
이 role들의 경우 일반적으로 사용되는 generic 데이터 role의 역할은 수행할 수 없게 된다.
- Content data node - 사용자가 생성한 콘텐츠를 수용하는 노드로 CRUD / Search / Aggregation 가능
node.roles: [ data_content ]- Hot data node - 엘라스틱 서치의 시계열 데이터를 저장 / 자주 사용되는 데이터 / 읽기 쓰기 모두 빠름
node.roles: [ data_hot ]- Warm data node - hot data만큼 정기적으로 업데이트되진 않지만 여전히 쿼리되는 인덱스 저장
node.roles: [ data_warm ]- Cold data node - 자주 사용되지 않는 데이터 (읽기 전용 인덱스)를 저장 / 성능이 낮은 하드웨어 사용 가능
node.roles: [ data_cold ]
Ingest Node
인제스트 노드는 일종의 데이터 전처리 파이프라인 역할을 수행하는 노드로
간단하게 엘라스틱 서치 내에서 로그스태시의 역할을 수행해주는 친구라고 보면 된다!
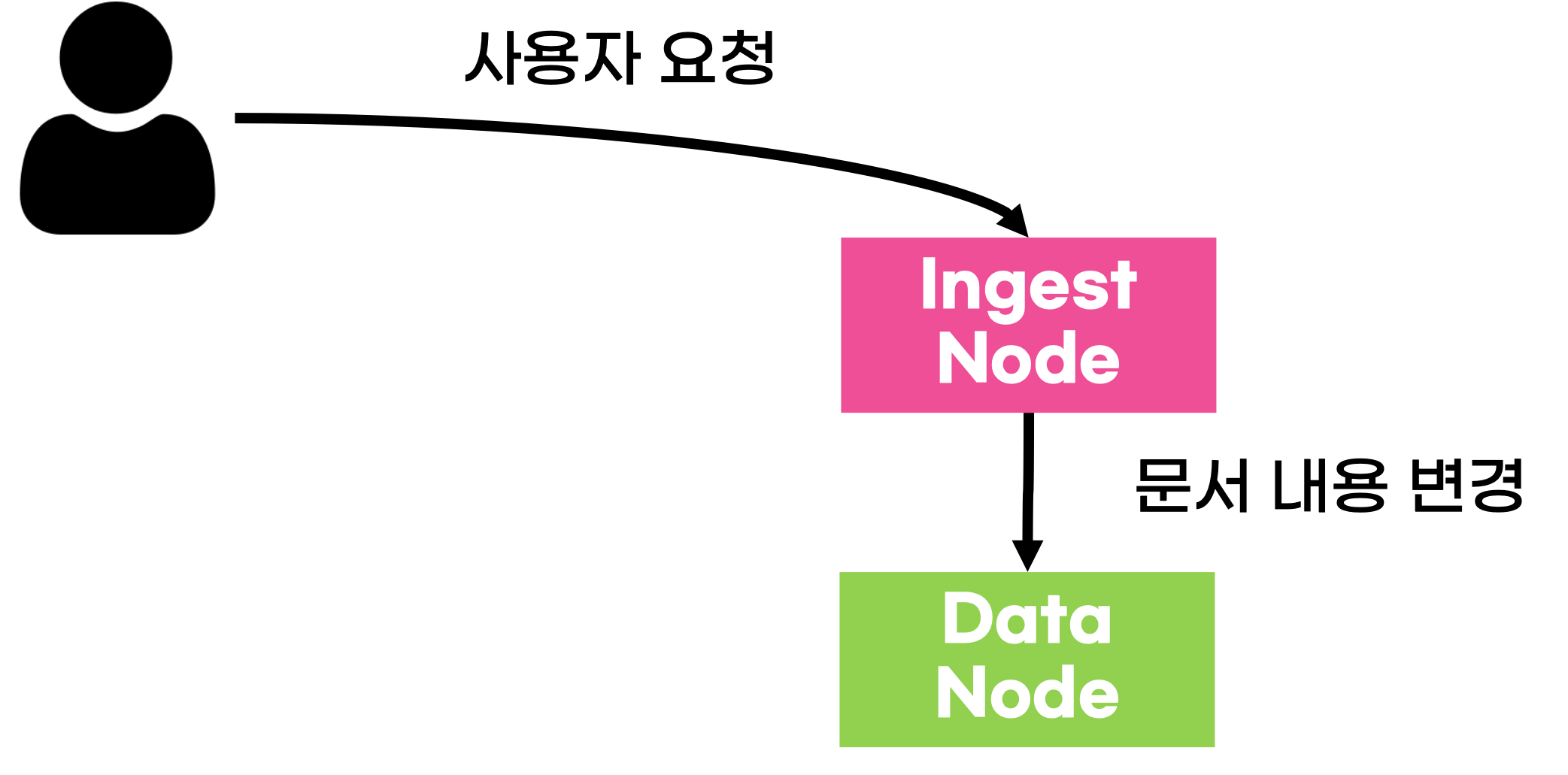
인제스트 노드 지정은 다음과 같이 가능하다!
node.roles: [ ingest ]여기까지 보다 보면 한 가지 의문이 들 것이라고 생각된다..!
로그스태시가 있는데 왜? 그와 유사한 기능을 하는 인제스트 노드가 엘라스틱 서치 내에 존재하는 것일까?
이에 대한 답은 굉장히 간단한데
과거에는 로그스태시가 존재하지 않았기 때문이다.
그렇기 때문에 엘라스틱 서치 내에서 데이터 전처리 기능이 필요했고
이를 위해 인제스트 노드가 존재하게 된 것이다.
하지만 현재는 엘라스틱 스택의 일원으로 로그스태시가 포함되어있고 비츠 또한 존재하기 때문에
엘라스틱을 처음 공부하게 되면 인제스트 노드를 사용할 일이 거의 없는데
사실 굳이 로그스태시를 사용하지 않고도 인제스트 노드만을 사용해서 전처리 파이프라인을 구축하는 것도
하나의 방법이 될 수 있다는 걸 알아두는 것도 좋을 것 같다!
Coordinating Only Node
코디네이트 노드는 데이터 노드처럼 실제 데이터를 저장하거나 사용자의 요청에 대해
요청을 수행하진 않지만, 요청들에 대해 전달과 그 결과를 취합하는 역할을 하는 노드이다.
일종의 load balancer라고 생각하면 된다!

코디네이트 노드는 앞서도 등장했듯이 노드의 역할에
아무것도 명시해주지 않는 것으로 지정이 가능하다.
node.roles: [ ]
Machine Learning Node
머신러닝 노드는 말 그대로 엘라스틱에서 제공하는
머신러닝 기능을 사용하기 위해 필요한 노드 role이다.
node.roles: [ ml, remote_cluster_client]오늘은 노드 role에 대해서만 다루기 때문에 따로 ml 기능에 대해 자세히 다루지는 않지만
궁금하다면 공식 다큐먼트의 Machine learning settings를 확인하는 걸 추천한다!
https://www.elastic.co/guide/en/elasticsearch/reference/current/ml-settings.html
Machine learning settings in Elasticsearch | Elasticsearch Guide [7.15] | Elastic
Do not configure this setting to a value higher than the amount of memory left over after running the Elasticsearch JVM unless you have enough swap space to accommodate it and have determined this is an appropriate configuration for a specialist use case.
www.elastic.co
그리고 처음 보는 "remote_cluster_client" 노드가 등장한 것을 볼 수 있는데
이는 클러스터 간 검색이나 복제 등을 가능하게 해주는 노드 role로서
ml 노드를 지정할 경우 선택적으로 부여하는 role이지만 공식 문서에 의하면
추가하는 것을 강력하게 권장하고 있다..!
Transform Node
트랜스폼 노드는 트랜스폼 api request와 트랜스폼을 담당하는 노드로
https://www.elastic.co/guide/en/elasticsearch/reference/current/transform-settings.html
Transforms settings in Elasticsearch | Elasticsearch Guide [7.15] | Elastic
It is strongly recommended that dedicated transform nodes also have the remote_cluster_client role; otherwise, cross-cluster search fails when used in transforms. See Remote-eligible node.
www.elastic.co
transform에 대한 자세한 내용은 공식 다큐먼트를 참고하길 바란다!
트랜스폼 또한 ml 노드와 마찬가지로 "remote_cluster_client" role을 추가해주는 것을 강력하게 권장하고 있다.
node.roles: [ transform, remote_cluster_client ]
결론
글을 쓰다 보니,,,, 예상과 다르게 길어져버렸다....
오늘 내용을 간단히 정리하면
- 엘라스틱 서치의 노드는 데이터를 저장하고 클러스터의 색인화 및 검색을 가능하는 역할
- 노드에는 다양한 role (역할) 존재
- 공식 다큐먼트를 애용하자!
정도이다..
마무리
오늘은 엘라스틱 서치의 클러스터를 구성하는 "노드"에 대해 살펴보았다.
글을 쓰면 쓸수록 느끼지만 애초에 목적이었던 정보 공유보단 개인 공부 목적으로 글을 쓰게 되는 것 같아
좀 아쉬움이 드는 것 같다..
이번 글은 개인적으로 미완성 상태의 글이라고 생각되는데 최대한 컨디션 돌아오는 대로 보완해볼 예정이다..!
오늘도 다들 화이팅~~!
※이 포스팅은 7.13 버전 기반으로 작성되었으며, 참고한 공식 Document 또한 동일 버전입니다.
※ 참고 자료 : https://www.elastic.co/guide/en/elasticsearch/reference/7.13/index.html
※ 참고 서적 : 기초부터 다지는 ElasticSearch 운영 노하우 - 박상헌, 강진우
'Data Engineering' 카테고리의 다른 글
| 2.1.3 엘라스틱 서치 구성 요소 및 구조 (인덱스/샤드/세그먼트) (0) | 2022.02.14 |
|---|---|
| 맥에서 하둡 설치하기 (1) | 2021.11.15 |
| 키바나 Map 활용 - 서울시 지하철 위치 데이터 (Index template) (0) | 2021.10.20 |
| 2.1.1 엘라스틱 서치의 구성 요소 및 구조 (클러스터) (0) | 2021.09.26 |
| 2.1 Elastic Stack - ElasticSearch (1) | 2021.08.28 |