들어가며..
시작에 앞서 현재 포스팅은 7.13.X 버전을 기준으로 작성됩니다. (현재 ES 버전은 7.14.x)
엘라스틱이 아무래도 버전 업데이트가 빠른 편이다 보니 공식 Document가 아닌 블로그 글 등을 읽을 때는
해당 글의 작성일자나 기준이 되는 버전을 먼저 확인하는 것을 추천한다.
추가적으로 잘못된 내용에 대한 지적은 언제나 환영합니다.
거의 한 두 달 만에 글을 쓰는 게으름뱅이지만, 오래간만에 쓰는 만큼 더 열심히 써야겠다,,
오늘 다뤄볼 내용은 엘라스틱 서치 (elastic search) 내부의 구성 요소와 구조에 대해 작성해보려 한다.
+ 글을 쓰다보니 또 내용이 길어져서 이 내용도 여러번에 나눠서 써야할 거 같다.....
+ 이번 글은 클러스터 먼저,,
우선 복습..! Elastic Stack이란?..
복습은 정말 재미없는 내용이지만, 전공 중 매주 게임 기획서를 발전시키고 발표하는 강의에서
교수님한테 "너는 네가 작성했던 모든 내용을 다 알겠지만, 다른 사람은 다시 말하지 않으면 모를 가능성이 99%이다"라는 이야기를 듣고
그 후로는 간단하게나마 이전의 내용을 다뤄보려고 하고 있다.
당장 엘라스틱으로 무언가 해야 하는 분들에게 내가 쓰는 글은 전혀 쓸모없겠지만 결국 내가 글을 쓰는 것도 자기만족이니까..!
그런 의미에서
Elastic Stack은 "실시간 데이터 수집, 분석, 검색엔진"이라고 말할 수 있다.
그리고 그중 오늘 다룰 엘라스틱 서치는 "검색과 분석"을 담당한다.
Elastic에서는 ElasticSearch를 Elastic Stack의 "심장"이라고 소개할 정도로 중요한 녀석이다.
ElasticSearch의 특징 요약
이전 포스팅에서 자세히 다룬 내용이지만, 간단히 짚고 넘어가면
엘라스틱은 다음과 같은 특징들을 가지고 있고, 이는 엘라스틱의 장점과도 직결되는 매우 중요한 요소들이다.

ElasticSearch 구성 요소
드디어 오늘의 주인공 엘라스틱 서치의 구성 요소에 대해 이모저모 살펴보도록 하겠다.
약간 TMI 하는 걸 좋아해서 그런지 서론이 길어진 건 기분 탓,,,

간단하게 구성 요소를 나타내 보면 5개 정도로 구분 지을 수 있다.
클러스터나 노드는 엘라스틱의 특징에서도 등장했고, 어려운 개념은 절대 아니다.
분량상 이번 글에서는 "클러스터"만 다뤄볼 예정이다.
클러스터
이쯤 되면 만만하고 친숙한 느낌의 클러스터일 것 같다.
아마 대부분 클러스터 개념은 알고 있을 것 같지만 복습 차원에서 설명하면
"여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합"이다.
그리고 이 개념을 엘라스틱 서치에 적용하면
"여러 대의 ElasticSearch Process들이 논리적 결합을 통해 하나의 ElasticSearch Process로 작동하는 것"
이라고 정리할 수 있다. (여기서 Elastic Process는 "노드"라고 불린다.)
클러스터 구조는 엘라스틱 서치의 성능과 안정성을 보장해주는 중요한 요소인데
간단하게 단일 노드로 구성된 클러스터와의 비교를 통해 이해할 수 있다.
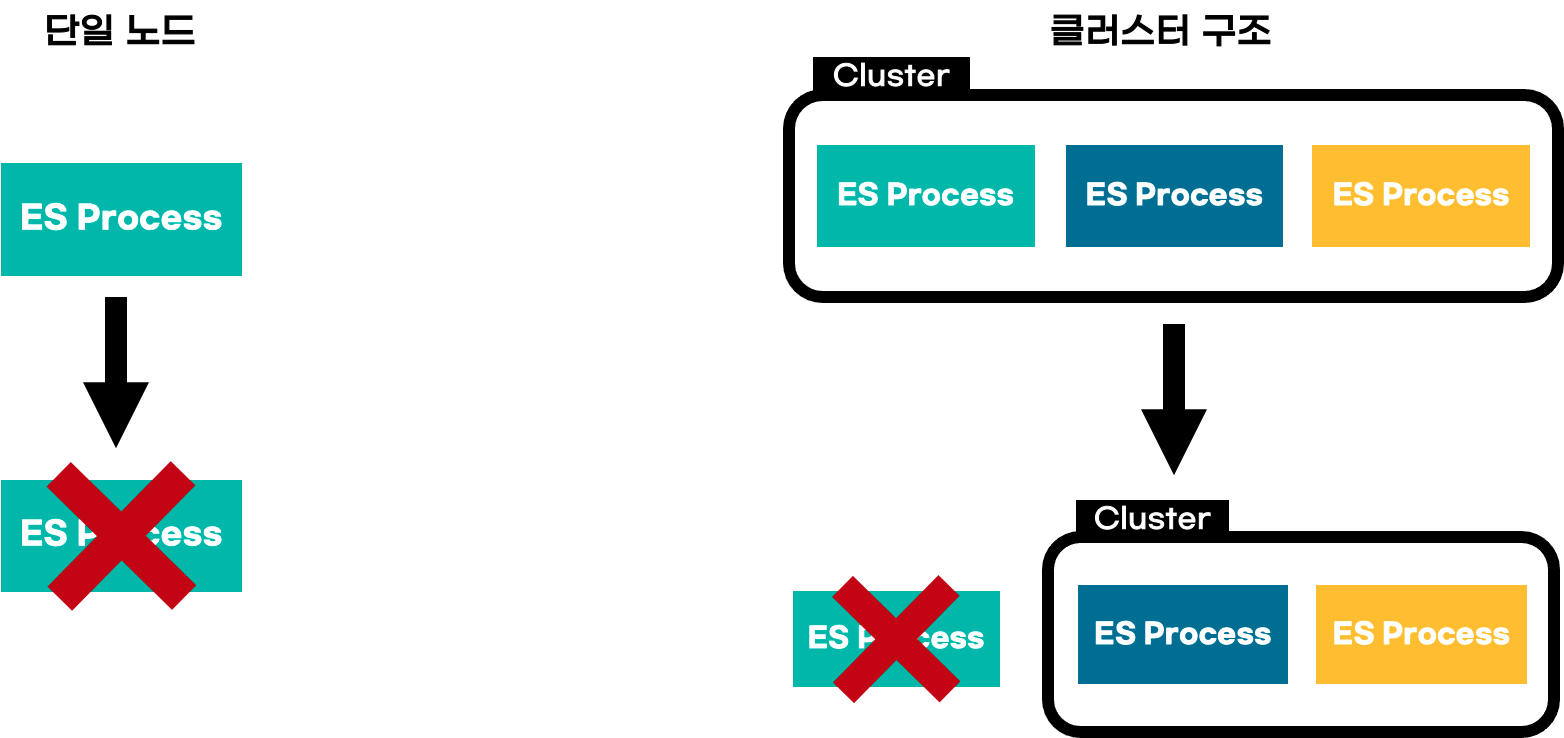
만약 엘라스틱 서치가 클러스터 구조가 아닌 단일 노드(ES Process)로 구성되어 있다면
이미지 좌측처럼 해당 노드에 문제 발생 시 서비스 전체가 shut down 되는 문제가 발생할 것이다.
하지만 우측처럼 여러 대의 노드로 구성된 클러스터 구조라면 그중 일부의 노드에 장애가 발생해도
나머지 노드들로 계속해서 클러스터 구조를 유지해 서비스를 운영할 수 있기 때문에 안정성이 보장되는 것이다.
여기서 한 가지 짚고 넘어가면 사실 엘라스틱은 단일 노드로 클러스터를 구성하는 것이 가능하긴 하다.
다만 그 경우 클러스터 구조를 채택한 의미가 퇴색되는 것이기 때문에 지양하는 것이 맞다.
근데 뭐,,, 사실 개인적인 공부나 테스트용으로 클러스터를 운용하는 거면 노드 한대도 충분하긴 하다.
노드 여러 대 실행시키는 것도 좀 귀찮기도 하고,,,
특히 local에서 실행하는 경우 자기 PC나 노트북이 빵빵한 램을 가진 경우 아니면 그냥 노드 한 대만 키는 걸로,,
클러스터의 구조
클러스터가 뭔지 알았으니, 클러스터가 어떻게 생겨먹은 건지도 알아야 하지 않을까? 해서 정리해보았습니다.

생각보단 복잡하진 않고
클러스터의 이름, id, 노드들로 이루어져 있다.
여기서 클러스터의 이름과 id는 클러스터별로 고유한 값을 가지는데
특히 이 2 가지 속성을 통해 노드들이 동일한 클러스터 내에 존재하는지 인식하고 클러스터링을 하게 된다.
클러스터의 역할
자 이제, 클러스터의 개념과 어떻게 생겨먹은지 구조도 살펴보았다.
그럼 역시 "그래서 얘가 뭘 하는 놈인데? 정확한 역할이 뭐야?"가 나올 차례이다.
그래서 준비했다. 클러스터는
"전체 데이터를 저장하고, 모든 노드를 포괄하는 통합 색인화 및 검색 기능을 제공"
결국엔 일종의 머리 역할이라고 보면 좋을 것 같다.
클러스터 작동 원리
사실 이 부분이 가장 중요하다고 개인적으로는 생각한다.
하지만 너무 자세히 들어가면 또 난리날 것 같아서 가장 중요한 포인트만 다뤄보려고한다.
기본적으로 클러스터는 elasticsearch의 config 디렉토리 아래 존재하는
elasticsearch.yml 파일을 기준으로 다양한 설정이 가능한데 특히 discovery 영역을 바탕으로 클러스터가 구축된다.
그리고 그 중 가장 중요한 설정은 일명 "최소 마스터 노드 대수 설정"이라고 불리는
"discovery.zen.minimun_master_nodes" 옵션이다.
마스터 노드라는 생소한 용어가 등장했지만, 일단 클러스터를 구성하는 노드들 중 대장 역할이라고 이해하면 된다.
그럼 이 "최소 마스터 노드 대수 설정"이 왜? 중요한지 알아보자
이를 설명하기 위해서는 먼저 "Split Brain"이라 불리는 현상에 대해 알아야한다.
정말 쉽게 설명하면 아마 내 동년배들은 한 번쯤 읽고 공포에 떨었을 "수일이와 수일이"를 생각하면 된다.
공부가 하기 싫었던 수일이가 자신의 손톱을 쥐에게 먹여 쥐가 또 다른 수일이가 되어 진짜 수일이가 집에서 쫓겨나는 그런 내용이다.
책의 줄거리에 빗대어 설명하면
특정 사건으로 인해 수일이가 둘이 되어 버리고 결국 나중에는 진짜 수일이가 누구인지 알 수 없어 문제가 발생하는 현상인데
특정 사건 -> 오류 혹은 네트워크 장애
둘이 되어 버리고 -> 클러스터가 둘 이상으로 쪼개지고
진짜 수일이 파악 불가 -> 실제 primary 클러스터 파악 불가
로 바꾸어 다시 말하면
Split Brain이란
네트워크 장애로 클러스터가 각 sub-cluster로 쪼개지고 서로 연결이 단절된 상태로 개별 작동하여 문제가 되는 것
이라고 간단히 말할 수 있다.
이제 다시 엘라스틱서치로 돌아와 엘라스틱서치에서 split brain은 어떻게 발생하고 해결하는지 살펴보자
몇 가지 사전 설명
1. 최소 마스터 노드 대수 설정 없음, 다시 말해 1대의 마스터 노드는 반드시 존재해야함
2. master eligible은 마스터 노드가 공석일 경우 마스터 노드로 선출될 자격을 가진 노드
3. 클러스터 내에서 master 역할이 가능한 노드는 master와 master eligible
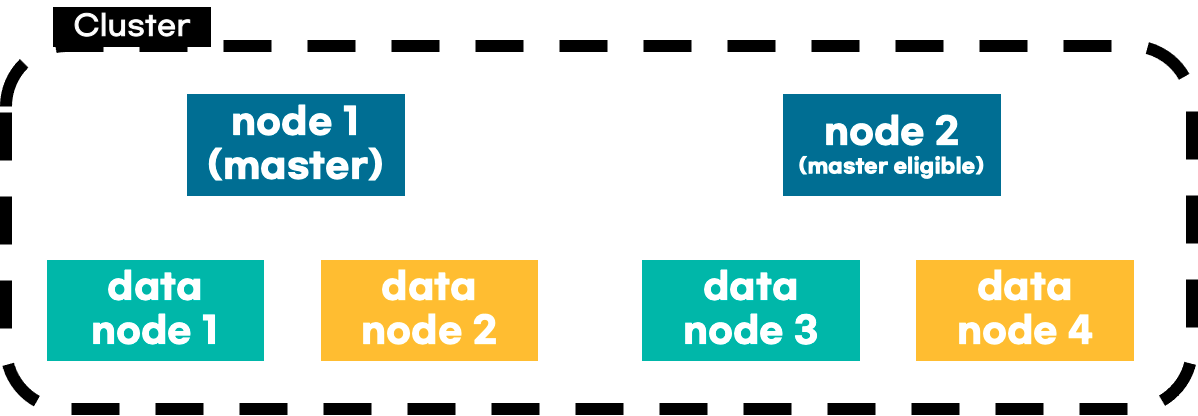
위 이미지와 같이 정상 상태를 유지하는 클러스터가 있다.

이때 네트워크 오류 혹은 다른 문제로 정상 클러스터가 두개로 분리가 되었다.
사전 설정을 기반으로 클러스터 내에는 1개의 마스터 노드만 존재하면 됨으로
좌측 클러스터는 기존의 마스터 노드가 마스터 역할을 계속 수행하여 정상 상태를 유지
우측 클러스터는 master eligible이 마스터 역할을 계승하여 정상 상태를 유지
-> 하나의 클러스터가 두 개의 클러스터로 분리
얼핏 보기에는 정상 -> 정상으로 문제가 없어보이지만
위와 같이 클러스터가 두 개로 분리된 상태로 둘 다 정상 작동을 하기 때문에 문제가 발생한다.
그러니까 둘 다 각자 정상 작동하며 변경 내역이 생기는 와중에
기존에 발생했던 문제 (네트워크 등)가 해결되어 다시 기존의 하나의 클러스터로 합쳐지게 되면
분리된 상태에서 각자 변경된 내용에 대해 동기화가 불가능해진다.
다시말해 "데이터 무결성"에 문제가 생기는 것이다.
그리고 이 현상을 엘라스틱 서치 내의 "Split Brain"이라 부른다.
그럼 엘라스틱 서치는 어떻게 이 문제를 방지하고, 해결하는 걸까?
앞서도 말했듯 "최소 마스터 노드 대수 설정"을 통해 방지하고 해결하고 있다.
하나의 클러스터 내에 반드시 존재해야하는 마스터 노드 (마스터 후보 수 포함) 개수를 설정하여
문제가 발생했을 시, 그 조건을 충족하지 못하는 부분은 더 이상 정상 작동하지 않고 죽여버리는 것이다.
엘라스틱에서는 기본적으로
마스터 후보 노드는 3 이상의 홀수 개
최소 마스터 노드 개수는 (전체 마스터 후보 수 / 2) + 1
로 설정할 것을 권장하고 있다.
이미지로 살펴보면
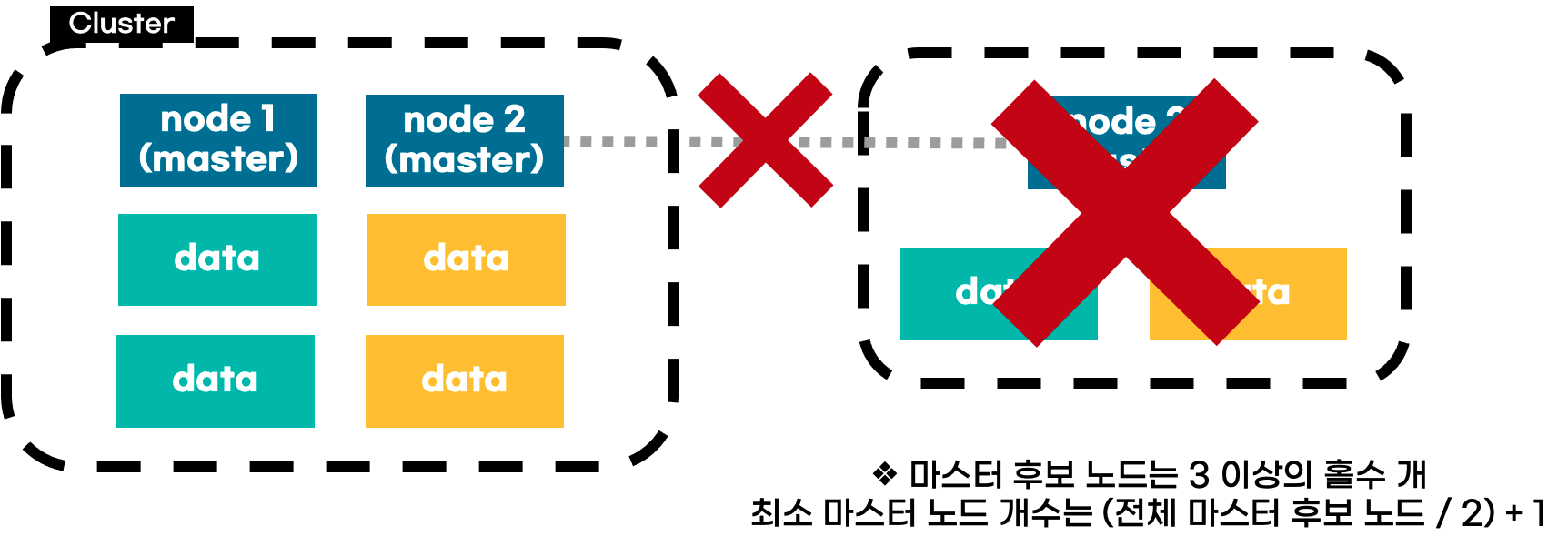
최초 상태에서 3개의 마스터 후보 노드를 가지고, 네트워크 유실 등의 문제로 분리되었는데
좌측은 최소 마스터 노드 대수인 (3 / 2) + 1 = 2를 만족하여 클러스터가 유지되지만
우측은 최소 설정을 만족하지 못하여 작동하지 않게 된다.
이처럼 최소 마스터 노드 대수 설정은 실제 서비스를 운용할때 상당히 신경써야 하는 요소로 주의 깊게 살펴봐야한다.
근데 또 사실 그냥 공부하거나 테스트할 때는 설정 안해도 된다... 뭐 중요한 데이터가 아니고 local 환경에서 구축할 경우
노드간 연결이 끊기는건 사용자가 직접 종료시키는 경우 말고는 없기 때문에... 그냥 편하게 해도 된다,,,
다만 실제 서비스를 운영할때는 진짜 진짜 반드시,,, 지켜야 하는 중요한 설정이다.
마지막으로 클러스터의 상태를 나타내는 Green, Yellow, Red 이런 개념이 있는데
이건 나중에 샤드 - primary, replica 개념을 알아야 쉽게 이해가 되기 때문에 샤드를 다룰 때
정리하는 것으로 하겠다.
결론
클러스터 세줄 요약
1. 클러스터는 엘라스틱서치의 안전성과 성능을 보장하는 구조이다.
2. 클러스터는 전체 데이터를 저장하고, 모든 노드를 포괄하는 통합 색인화 및 검색 기능을 제공한다.
3. 클러스터에서 Split brain 현상을 방지하기 위한 "최소 마스터 노드 대수 설정"이 매우 중요하다.
마무리..
오늘은 ElasticSearch의 구성 요소 중 가장 큰 덩어리인 "클러스터"에 대해 정리해보았다.
빠른 시일 내로 다음 친구들에 대해 다뤄보겠다,,,
화이팅,,
※이 포스팅은 7.13 버전 기반으로 작성되었으며, 참고한 공식 Document 또한 동일 버전입니다.
※ 참고 자료 : https://www.elastic.co/guide/en/elasticsearch/reference/7.13/index.html
※ 참고 서적 : 기초부터 다지는 ElasticSearch 운영 노하우 - 박상헌, 강진우
'Data Engineering' 카테고리의 다른 글
| 2.1.2 엘라스틱 서치의 구성 요소 및 구조 (노드) (0) | 2021.11.02 |
|---|---|
| 키바나 Map 활용 - 서울시 지하철 위치 데이터 (Index template) (0) | 2021.10.20 |
| 2.1 Elastic Stack - ElasticSearch (1) | 2021.08.28 |
| Elastic Scripting으로 승률 계산 (1) | 2021.07.21 |
| 1. 목적성,, (0) | 2021.07.19 |