들어가며..
엘라스틱에 관한 첫 번째 글을 드디어 쓰게 되었다.
간단한 소개와 왜 엘라스틱이 좋은지에 대한 내용을 정리해보려 한다.
시작에 앞서 현재 포스팅은 7.13.X 버전을 기준으로 작성된다는 사실을 알린다.
엘라스틱이 아무래도 버전 업데이트가 빠른 편이다 보니 그만큼 공식 문서의 변화도 잦아 블로그 글 등을 읽을 때는
해당 글의 작성일자나 기준이 되는 버전을 먼저 확인하는 것을 추천한다.
추가적으로 잘못된 내용에 대한 지적은 언제나 환영합니다.
글을 쓰다 현생이 바빠서 마무리를 못하던 중에 엘라스틱이 또 업데이트 됐다....
현재 최신은 7.14 버전으로 일단은 블로그 포스팅은 기존 7.13 버전을 기반으로 작성하겠지만
추가적인 변경 사항도 다룰 수 있으면 다뤄보는걸로.....
Elastic Stack이란?..
Elastic Stack에 대해 설명하기 위해 Elastic의 말을 빌려오자면 아래와 같이 정리할 수 있다.
"모든 형태의 모든 소스에서 데이터를 가져오고 실시간으로 검색, 분석, 시각화하세요"
사실 잘 와닿지 않는 인위적인 멘트여서 조금 더 풀어서 설명하면 결국
Elastic Stack은 "실시간 데이터 수집, 분석, 검색 엔진" 이다.
여기서 검색에 강조를 한 이유는 엘라스틱의 근본이 바로 검색 엔진이기 때문인데 이는 차차 살펴보도록 하겠다.
Elastic Stack의 구조
엘라스틱 스택에 대해 알기전에 어떤 놈들로 구성되어 있는지 알아보자
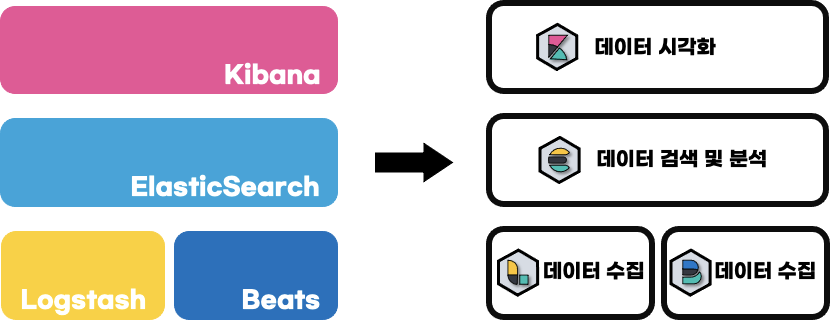
간단히 구성 요소들을 나타내면 위와 같다.
Logstash, Beats, ElasticSearch, Kibana 총 4개로 구성되어 있고
로그스태시와 비츠는 데이터 "수집"을
엘라스틱 서치는 "검색과 분석"을
그리고 키바나는 "시각화"를 담당한다.
비츠가 Elastic Stack의 구성요소로 들어오게된 것은 비교적 최근(?) 일인데
그전에는 ElasticSearch, Logstash, Kibana의 앞 글자를 딴 ELK Stack이라고 불렸던 적이 있다.
그래서인지 최근에도 ELK Stack이라 부르는 사람들이 종종 있으니
ELK Stack == Elastic Stack 으로 보면 된다.
그럼 이제 간단한 소개는 마무리하고, 본격적으로 Stack의 구성 요소들을 살펴보자
가장 먼저 Elastic Stack의 "심장"이라 불리는 ElasticSearch에 대해 알아보자
ElasticSearch란?..
엘라스틱이 좋다 좋다 다들 말하는데, 과연 엘라스틱은 무엇인지에 대해 한번 알아보자

엘라스틱 서치는 루씬 기반의 오픈 소스 검색 엔진으로
초기엔 전문 검색 엔진 (Full Text Search Engine)으로 개발되었으나
현재는 보안, 로그 분석을 비롯해 기본적인 전문 분석 등 다양한 분야에 사용되는
한마디로 "검색 엔진"이라고 할 수 있다.
이 설명을 처음 들었을 땐, 적어도 내 기준에선 난생처음 들어보는 단어가 2개나 나왔다.
전문 분석에 대해서는 추후에 자세히 설명할 테니 제외하고 루씬만 간단히 보면
자바 기반의 검색 엔진 라이브러리라고 할 수 있다.
그럼 또 이런 의문이 들 수도 있다.
"루씬도 검색 엔진이고, 엘라스틱도 검색 엔진이면 그냥 루씬 쓰지 엘라스틱은 왜 만든 거지?"
눈치 빠른 사람들은 이미 알아챘을 수도 있지만, 설명하자면
루씬은 라이브러리이고, 엘라스틱은 어플리케이션이라는 차이점 때문이다.
둘 다 같은 검색 엔진이고, 같은 기능을 하더라도 라이브러리인 루씬의 경우 사용의 불편함 등의 한계가 존재하고
이를 극복하고자 엘라스틱이 개발된 것이다.
간단한 비유를 통해 설명해보면
조립식 컴퓨터를 맞출 때 다X와 에서 메인보드, 파워, CPU, GPU, 램, SSD 등등 을 개별 구입 후
스스로 조립해 완제품을 만드는 과정이
루씬이라는 라이브러리(각 부품)를 사용해 검색 엔진(컴퓨터)으로 써 기능을 하게 하는 것이라면
엘라스틱은 원하는 스펙 대의 완제품 PC를 고르고 구매해 바로 사용하는 것이라고 할 수 있다.
물론 전자의 경우가 더 효율적이라고 생각할 수도 있지만 전문 지식이 없는 일반 사용자 입장에선
비용을 조금 더 지불하더라도 후자를 택하는 것이 합리적이라는 것에 모두 동의할 것이다.
둘의 비교는 이정도로 끝내고, 어느 정도 이해는 됐을 것이라 생각한다.
그럼 본격적으로 왜 엘라스틱이 좋다고하는지에 대한 이야기를 해보겠다.
Elastic의 특징

Elastic의 특징을 표로 정리해보면 위와 같이 나타낼 수 있다.
Elastic이 ElasticSearch를 포함하는 좀 더 큰 의미이지만, 결국 Elastic의 핵심은 ElasticSearch이기에
Elastic의 특징은 곧 ElasticSearch의 특징이라고 할 수 있다.
또한 앞으로 두 단어를 같은 의미로 사용할 예정이니 혼동 없이 이해하면 좋을 것 같다.
그럼 각 특징에 대해 자세히 살펴보자
준실시간 검색 엔진 (Near Real-Time)
단어에서부터 알 수 있듯이 실시간은 아니지만,
사실상 실시간에 가까운 속도로 데이터 색인과 검색, 집계 등이 가능하다는 특징이 있다.
이는 엘라스틱의 빠른 검색과도 어느 정도 일맥상통하는 특징인데
하둡과 같은 배치 기반 시스템처럼 데이터, 프로그램 등을 미리 올려두고 결과를 도출하는 방식이 아닌
클러스터가 실행중인 동안에는 refresh_interval (default : 1s)이라는 일정 시간마다 데이터를 저장하는 방식으로
사실상 실시간에 가까운 속도로 데이터 저장, 검색, 집계가 가능하다.

이미지를 통해 살펴보면 "name" : "integer"라는 JSON 문서가 입력되면
우선 메모리에 저장되었다가, 1초 후에 샤드에 저장되고 그 후에 검색과 집계 등이 가능한 것을 알 수 있다.
샤드에 대해서는 앞으로 다룰 예정이라 루씬의 단일 검색 인스턴스 정도로 간단하게 이해하면 좋을 것 같다.
전문 검색 엔진 (Full Text Search Engine)
다음은 전문 검색 엔진에 대해 살펴보자.
검색어와 일치하는 단어가 있는지 모든 문서의 모든 단어에 대해 검색하는 방식으로
얼핏 보기엔 굉장히 비효울적인 방법으로 보인다.
하지만 여기에 하나 중요한 포인트가 있는데
전문 검색에서의 모든 문서의 단어들은 색인의 형태로 저장되어있다는 점이다.
그럼 또 색인은 무슨 뜻이란 말인지 알아보지 않을 수 없게 되었다.
여기서 잠깐 삼천포로 빠지면 항상 느끼는 거지만, 엘라스틱은 공부를 하면 할수록 공부해야 하는 양이 늘어나는 것 같다..
개념 하나에 대해 공부를 하다 보면, 그것과 연관 있는 개념 2~3개가 튀어나오는,,, 메두사도 아니고 참,,
어쨌든 색인에 대해 사전적 개념을 가져와 이야기를 해보자면
데이터를 기록 시 데이터의 이름, 데이터 크기 등의 속성과 그 기록 장소 등을 표로 표시하는 것.
라고 한다.
물론 한 번에 와닿는 설명은 아니지만, 중요한 키워드에 집중해보면 조금 더 쉽게 이해가 될 것이다.
색인이란
데이터를 저장 시 표의 형태로 해당 데이터의 속성(이름, 크기)과 데이터의 위치 정보를 표현하는 것.
으로 바꿔 말할 수 있다.
부가설명을 하자면, 데이터를 저장할 때 단순히 데이터만 저장하는 게 아니라
데이터가 문서 내에서 어느 위치에 혹은 어느 문서에 위치하는지를 같이 나타내는 것을 말한다.
간단히 책 앞에 있는 목차를 떠올린다면 쉽게 이해가 될 것이라 생각한다.
여기까지 이해를 했다면, 아마 이런 생각이 들 수도 있다. 아닐 수도 있지만
"특정 데이터(단어)가 여러 번 등장하면 어쩌지?"
책의 목차는 범주화가 되어 중복이 없는 데이터들이지만,
책의 내용을 저장한다면 데이터(단어)의 중복은 필연적이기 때문이다.
그래서 전문 검색에는
역 파일 색인(Inverted File Index)이라는 개념이 존재한다.
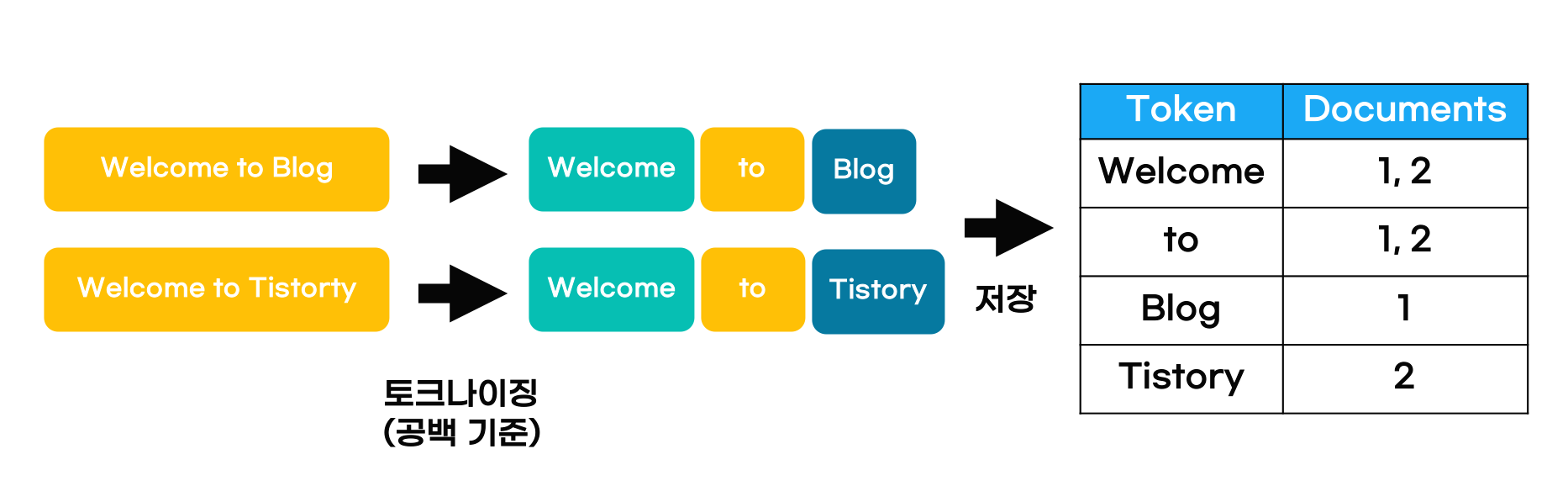
역 파일 색인 구조는 일반적인 색인 구조와 다르게 그 역의 형태를 취하면서
각 데이터들이 어느 문서 혹은 위치에 존재하는지 테이블의 형태로 나타내는 것을 의미한다.
그리고 엘라스틱은 이 역 색인 구조를 통해 빠른 검색을 자랑할 수 있는 것이다.
RDBMS와 다르게 엘라스틱은 검색하고자 하는 단어를 토큰으로 변경하고, 해당 토큰의
위치정보를 모두 가지고 있기 때문이다.
클러스터 구조
엘라스틱의 클러스터 구조는 엘라스틱의 안정성과 부하 분산을 가능하게 하는 핵심 요소라고 할 수 있다.
클러스터의 개념에 대해서도 마찬가지로 사전적 의미를 살펴보면 다음과 같다.
여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합
조금 의미가 다를수도 있지만 RPG 게임에서 보스 레이드를 할 때
솔로 플레이보다는 파티 플레이가 안정성이 높아지는 것을 떠올리면 금방 와닿을 것 같다.

엘라스틱에서의 클러스터 구조를 조금 더 자세히 설명하면 위 이미지와 같이
여러 개의 엘라스틱 프로세스들을 논리적인 결합을 통해 하나의 엘라스틱 프로세스처럼 사용하게 하는 것이다.
그리고 여기서 클러스터를 구성하는 엘라스틱 프로세스는 "노드"라는 이름으로 불리는데
이 부분에 대해서는 다음 포스팅 혹은 그 이후에 자세히 다루고 지금은 간단히 넘어가겠다.
스포를 조금 하자면, 각 노드들에는 역할을 지정할 수 있고, split brain이라 불리는 현상을 방지하기 위한
여러 설정, 각 노드 역할의 특징 등 재밌는 내용으로 구성되어있으니 기대해도 좋을 것 같다.
스키마리스
스키마리스는 엘라스틱과 RDBMS 간의 가장 큰 차이 중 하나라고도 할 수 있는 특징이다.
RDB에서 사전에 스키마를 정의해주어야 하는 것과 달리
엘라스틱에서는 데이터 input시에 데이터를 분석하고 그에 적절한 스키마를 생성해준다.
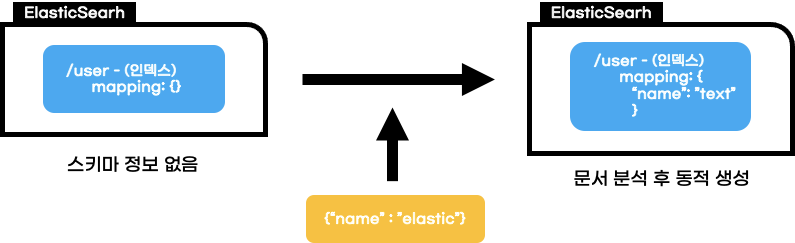
이때 엘라스틱은 각 데이터 필드에 대해 해당 필드를 수용할 수 있는 데이터 타입들 중
가장 큰 데이터 타입을 선정해 스키마를 생성해주는 특징도 가지고 있다.
예를 들어, { "count" : 5 }라는 데이터를 input하게 되면 5에 적합한 integer 타입이 아닌
이를 수용할 수 있는 가장 큰 범위인 long 타입으로 생성되는 구조이다.
조금 더 설명하자면, 엘라스틱의 "스키마리스"는 엘라스틱의 "장점"이라기보다는
하나의 "특징" 정도로만 이해하는 것이 적합하다.
이는 동적 스키마 생성으로 인해 문제가 발생하는 경우(특히 numeric type에서)가 존재하기 때문인데 추후에 자세히 다뤄보도록 하겠다.
REST API
마지막으로 소개할 엘라스틱의 특징은 바로 REST API 기반의 인터페이스를 지원한다는 점이다.
덕분에 어떤 언어로도 클라이어트 개발이 가능하게 되는데
엘라스틱에서도 공식적으로 자바, 파이썬, 자바스크립트 등의 언어에 대해 클라이언트 API를 공식적으로 제공해주고 있다.
그리고 이것들을 스프링, 장고 등과 함께 활용한다면 엘라스틱을 DB로 활용하는 서비스 개발이 가능하다.
결론
이정도의 설명을 들으면 아마 다들 "그래서 뭐?"라는 생각이 들것이다.
단순히 엘라스틱서치가 가진 특징 몇가지 만으로 전체적인 이해를 돕는 것은 어려울 수 밖에 없기 때문인데
이번 포스팅의 내용은 간단한 튜토리얼 정도로만 생각하고 앞으로 이어지는 포스팅에서
더 자세히 엘라스틱 스택에 대해 다뤄보도록 하겠다.
마무리..
오늘은 Elastic Stack과 ElasticSearch에 대한 간단한 소개를 담아보았다.
순서상으로는 Logstash와 Kibana, Beats에 대해서도 서치처럼 소개를 먼저 하는게 맞는건가 싶기도하지만
차곡차곡 돌을 쌓아올리듯이 엘라스틱 서치의 내용을 먼저 다루고 로그스태시와 비츠 키바나 등을
다루는게 맞는 것일지 상당히 고민이된다.
그런 의미에서 다음 포스팅은 스택의 나머지 구성 요소들에 대한 간단한 소개 혹은
엘라스틱 서치에 대해 더 자세히 (클러스터 구조, 노드, 인덱스 등등) 다뤄보려고 생각하고 있다.
아마 후자를 다룰 가능성이 높긴하다,,
그나저나 이 글을 처음 쓰기 시작한게 7월 중순이었는데, 어느새 8월 말이되고
이제서야 글을 공개하게 되었다. 정말 내 방학 어디간거지..
※이 포스팅은 7.13 버전 기반으로 작성되었으며, 참고한 공식 Document 또한 동일 버전입니다.
※ 참고 자료 : https://www.elastic.co/guide/en/elasticsearch/reference/7.13/index.html
※ 참고 서적 : 기초부터 다지는 ElasticSearch 운영 노하우 - 박상헌, 강진우
'Data Engineering' 카테고리의 다른 글
| 2.1.2 엘라스틱 서치의 구성 요소 및 구조 (노드) (0) | 2021.11.02 |
|---|---|
| 키바나 Map 활용 - 서울시 지하철 위치 데이터 (Index template) (0) | 2021.10.20 |
| 2.1.1 엘라스틱 서치의 구성 요소 및 구조 (클러스터) (0) | 2021.09.26 |
| Elastic Scripting으로 승률 계산 (1) | 2021.07.21 |
| 1. 목적성,, (0) | 2021.07.19 |