들어가며..
시작에 앞서 현재 포스팅은 7.13.X 버전을 기준으로 작성됩니다. (현재 ES는 8.0 버전도 공개가 되었다,,,,,)
엘라스틱이 아무래도 버전 업데이트가 빠른 편이다 보니 공식 Document가 아닌 블로그 글 등을 읽을 때는
해당 글의 작성일자나 기준이 되는 버전을 먼저 확인하는 것을 추천한다.
추가적으로 잘못된 내용에 대한 지적은 언제나 환영합니다.
이게 얼마 만에 엘라스틱 카테고리에 글을 작성하는지 모르겠다!
마지막 학기를 다니면서 여러모로 준비할 것들을 준비하다 보니 자연스레 블로그에
열중하지 못한 듯했지만 그래도 재미난 주제들을 많이 생각해둬서
시간이 날때마다 금방 포스팅을 완성해볼 수 있을 것 같다!
그럼 시작해보자!
오늘의 주제
자 오늘은 엘라스틱 서치의 구성 요소 시리즈의 마지막 포스팅
인덱스, 샤드, 세그먼트를 한 번에 다뤄보도록 하겠다.
이것들은 데이터가 실질적으로 저장될 때 깊게 관여하는 친구들인데
세 친구들 사이의 연관성도 존재하기 때문에 한 번에 글을 작성하게 되었다!
마찬가지로 전혀 어렵지 않은 재미난 내용들이니 찬찬히 읽어보기를 추천한다.
엘라스틱 서치 구성 요소 (복습)
역시나 빼놓을 수 없다. 복습..!
간단하게 살펴보자 엘라스틱 서치 내에는 다음과 같은 녀석들이
중요한 역할을 하면서 엘라스틱 서치를 구성하고 있다!

그리고 오늘은 위에도 언급했듯 아래 3 친구를 순서대로 다뤄볼 예정이다.
Index (인덱스)

먼저 인덱스이다.
인덱스는 ES에서 단일 데이터 단위를 뜻하는 "도큐먼트(document)"의 집합으로
잠시 후에 다룰 "샤드"라는 단위로 분리되고, 각 데이터 노드에 분산 저장된다.
이는 데이터의 무결성을 보장하고, 검색 성능을 향상하는데 중요한 요소로서 작용하게 된다.
여기서 도큐먼트는 비슷한 특성을 가진 문서들이 모음을 의미하는데
완벽한 비유는 아니지만 RDBMS에서의 테이블과 그나마 유사하다고 볼 수 있다.
한 인덱스에서 사용되는 설정이나 도구들은 다른 인덱스에 영향을 주지 않는데
위 이미지를 예를 들어보면 Movie Index에 특정 설정이 적용되었다고 하더라도
이는 Book Index에 적용되지 않는다는 것이다!
또한 각 인덱스는 이름을 가지고 있어 식별할 수 있게 된다.
이름은 소문자로 구성되어야 하며, 해당 이름을 가지고 인덱스 내의 문서에 대해
색인화, 검색, 업데이트, 삭제 등의 작업을 수행할 수 있게 된다!
인덱스에 관해서 다룰 내용은 많은 편이지만 뒤에 나올 샤드와 세그먼트를 이해하고
그다음에 내용을 다루는 것이 더 좋을 것 같아 우선 인덱스에 관한 설명은 이 정도로 마무리,,,
Shard (샤드)
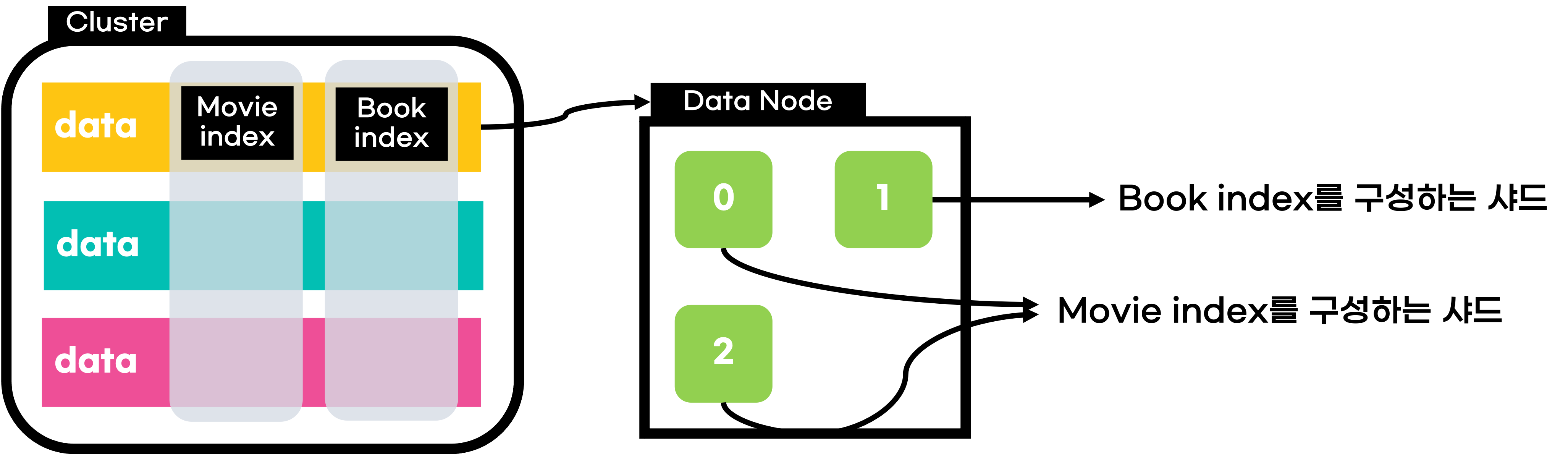
샤드는 루씬의 단일 검색 인스턴스이자
인덱스에 색인되는 문서들이 저장되는 논리적인 공간을 의미한다.
특히 샤드는 프라이머리 샤드와 레플리카 샤드
각각 원본과 복제본을 의미하는 두 종류로 나누어지는데
ES 7.0 버전 이후부터는 원본 (프라이머리 샤드)의 개수가 기본 1개
그 이전 버전을 사용할 경우 기본 5개의 프라이머리 샤드를 가진다.
특히 이 프라이머리 샤드의 개수는 최소 인덱스를 생성할 때 설정 가능하고
그 이후에는 변경할 수 없기 때문에 주의해야 한다!
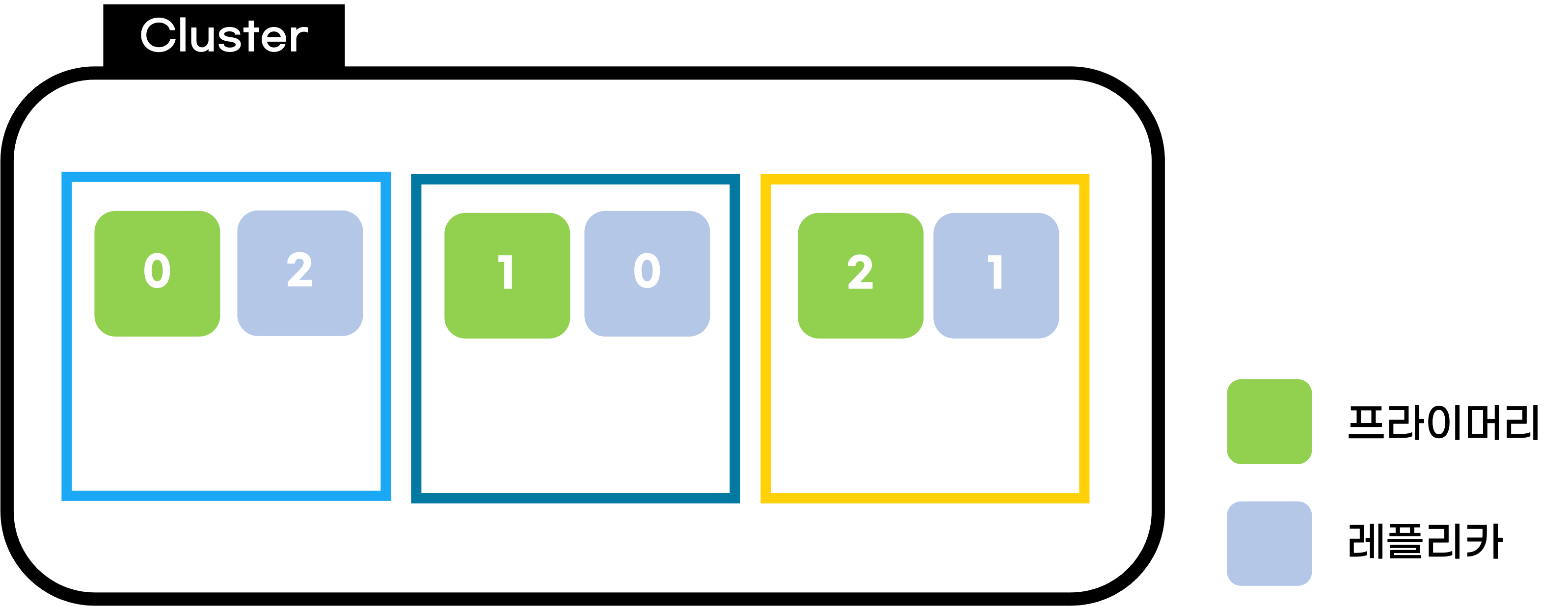
프라이머리 샤드와 레플리카 샤드에 대해 더 자세히 알아보자!
각각 원본 데이터와 백업용 복제 데이터 정도의 개념으로 이해하면 이해가 쉬운데
엘라스틱서치의 데이터 유실을 방지하고 데이터 가용성과 무결성을 유지하기 위한 중요한 설정이다.
위 이미지를 바탕으로 계속 이야기해보겠다.
먼저 현재 클러스터는 3개의 노드로 구성되어있고, 모든 노드가 데이터 노드의 role을 수행 가능하다고 가정하겠다.
이때 프라이머리 샤드의 개수가 3으로 설정된 인덱스가 클러스터 내에 존재한다고 해보자.
이 경우 각 데이터 노드에 프라이머리 샤드가 1개씩 총 3개가 배치가 되고
프라이머리 샤드 1 개당 백업용, 레플리카 샤드가 1개씩 존재하여 마찬가지로 각 노드에 하나씩 배치된다.
이때 동일한 데이터를 포함하는 프라이머리 샤드와 레플리카 샤드는 같은 노드 내에 존재할 수 없게 설정이 되어있다.
당연한 이야기겠지만, 원본과 백업용 데이터를 같은 하드디스크에 보관하는 것은 백업용 데이터의 의미가 퇴색되고
그저 저장 장치의 용량만 차지하는 것과 동일한 현상이기 때문이다.
이어서 프라이머리와 레플리카 샤드가 과연 어떻게 데이터 유실을 방지하고 가용성과 무결성을 보장하는지
실제 문제 상황을 살펴보고, 추가적인 cluster health status와 연관 지어 살펴보자
Cluster Status - Green, Yellow, Red
엘라스틱서치 내의 클러스터의 status는 3가지 단계로 나뉜다.
간단하게 신호등의 초록, 노랑, 빨강 불을 생각하면 좋은데
Green은 클러스터를 안정적으로 운영하고 데이터에 문제가 발생되지 않은 상태
- 프라이머리 샤드, 레플리카 샤드 모드 안정적
Yellow는 클러스터 운영은 가능하나 데이터 유실의 가능성이 존재하는 상태
- 프라이머리 샤드는 온전히 존재하나, 레플리카 샤드 배치 불가
Red는 클러스터 운영이 불가하며 데이터가 유실된 상태
- 프라이머리 샤드가 1개 이상 유실된 한 마디로 큰일 난 상태,,,
정도로 정리해 볼 수 있다.
이와 같은 규칙에 의하면
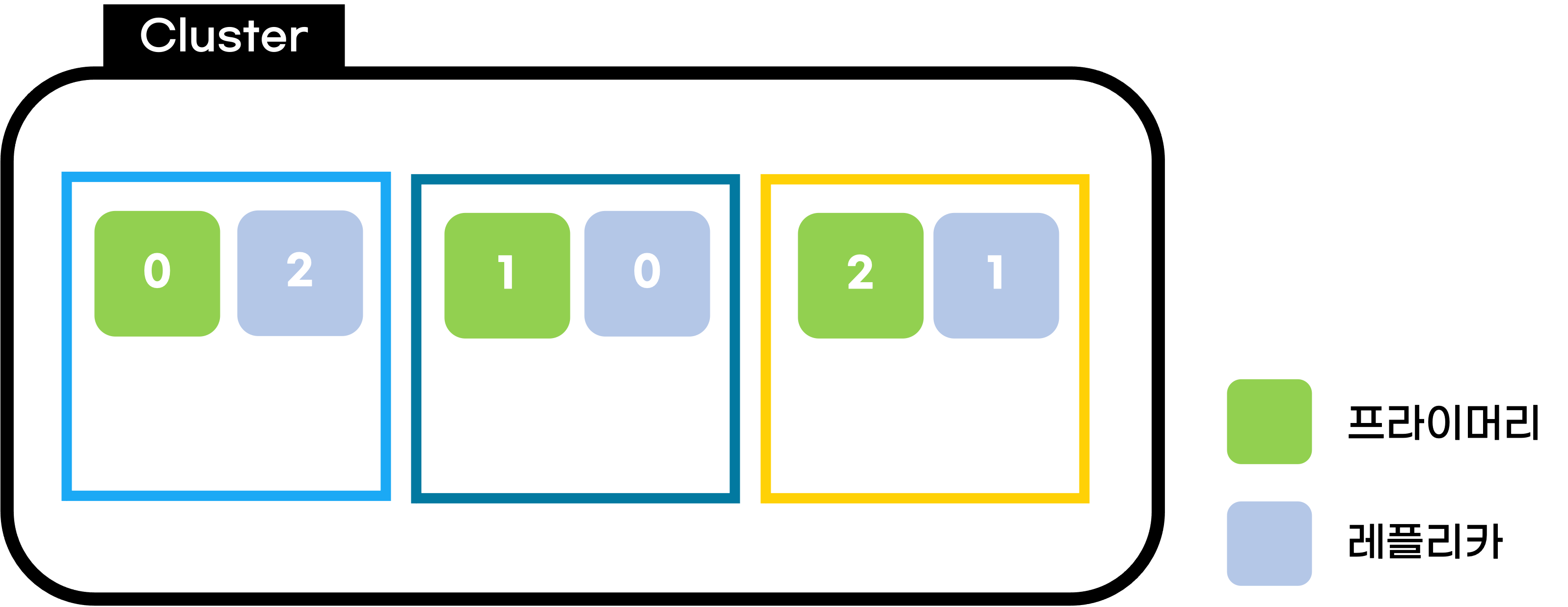
아까부터 계속 나오는 이 이미지는 Green 상태인 것을 우리는 알 수 있다.
그럼 이제 문제 상황을 하나씩 가정해보며 어떤 방식으로 클러스터의 stauts가 유지되는지 살펴보자
Step 1. 네트워크 유실 등의 문제로 데이터 노드 문제 발생

데이터 노드 하나에 문제가 발생해
1번 프라이머리 샤드와 0번 레플리카 샤드가 유실된 상황이 되었다.
이 경우 엘라스틱 서치의 클러스터는 자동적으로 유실된 1번 프라이머리 샤드를 복구하기 위해
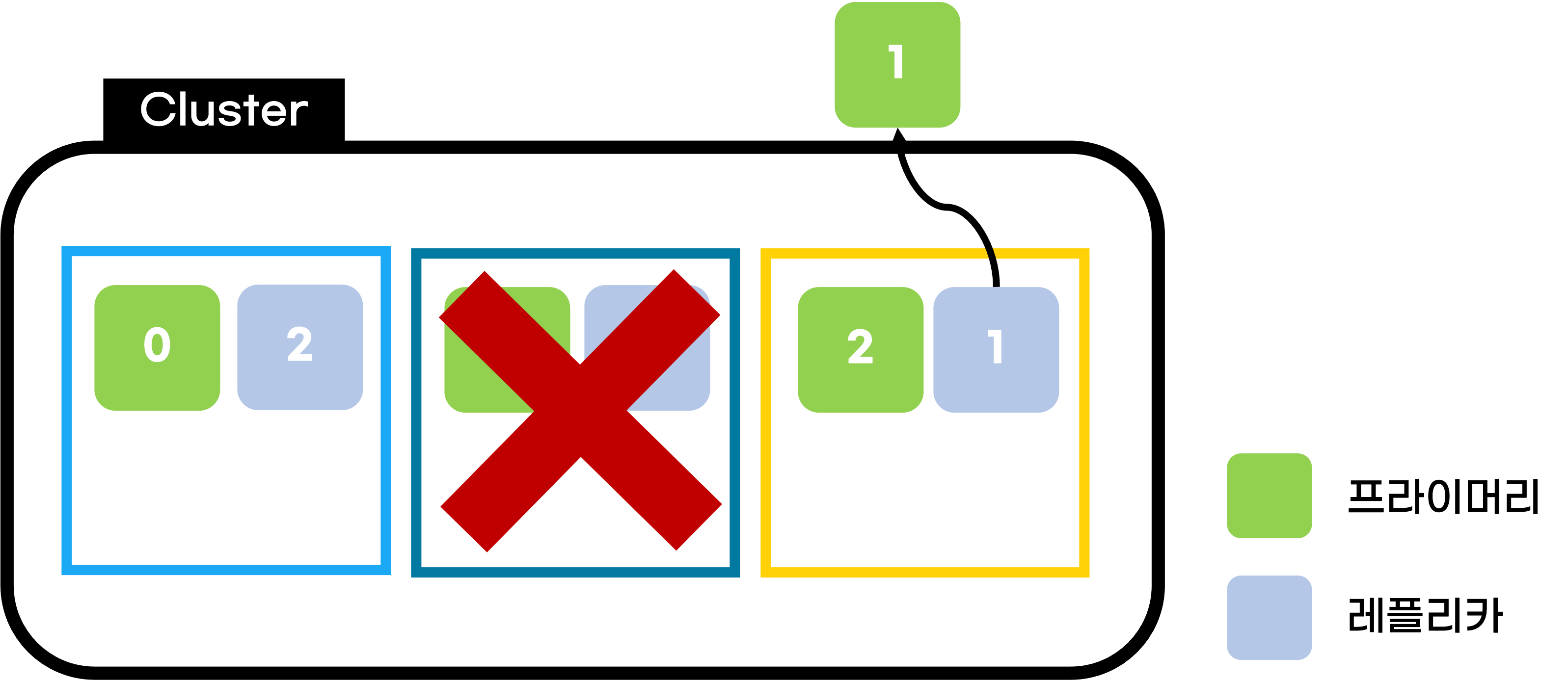
3번 데이터 노드에 저장되어 있던 1번 레플리카 샤드를 프라이머리 샤드로 승격시키게 된다.

그리고 이어서 새로운 1번 레플리카 샤드를 생성해주게 된다.
이미지 상에는 0번 레플리카 샤드가 추가되지 않았지만
정상적이라면 프라이머리 샤드와 다른 위치인 3번 데이터 노드에 0번 레플리카가 생성되며
다시 Green Status를 유지할 수 있게 된다.
Segment (세그먼트)

세그먼트는 샤드의 데이터들을 가지고 있는 물리적 파일들로
실제 데이터가 저장된 물리적 위치를 말한다.
그리고 이렇게 물리적으로 데이터를 저장하는 행위는 비용이 굉장히 많이 드는데
이를 위해 세그먼트는 두 가지 특징
불변성과 병합이라는 특성을 가진다.
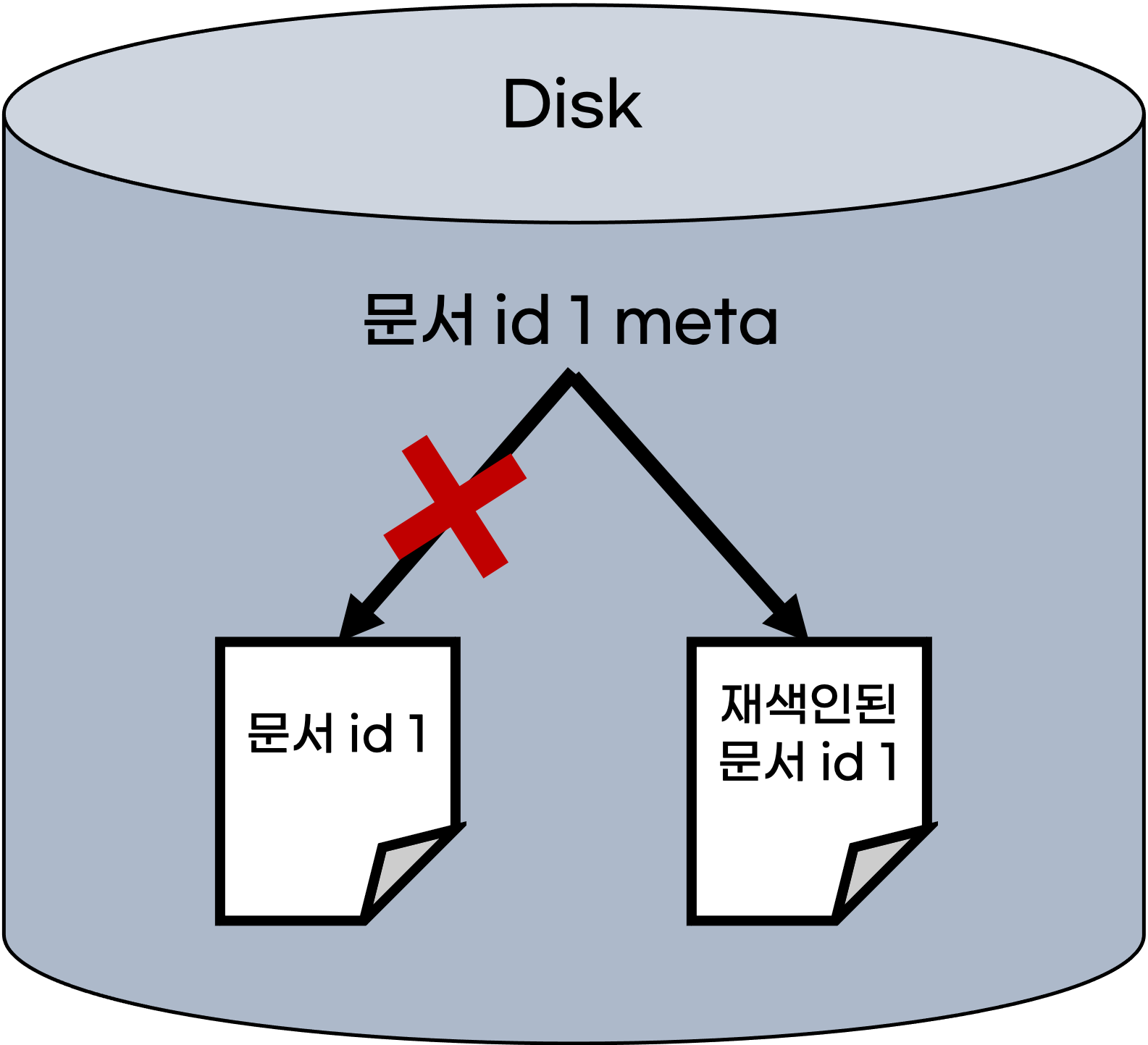
먼저 불변성은 기존에 기록한 데이터를 업데이트(변경) 하지 않은 특성인데
동일 id를 가진 문서를 재색인 할 경우 기존 데이터를 변경하는 것이 아니라
새로운 문서를 작성하여 저장하게 된다.
그리고 기존의 문서에 대해서는 삭제가 아닌 불용 처리를 하게 되는데
앞서도 말했듯, 실제로 데이터를 쓰고 지우는 행위는 비용이 매우 크기 때문이다.
이렇게 불용 처리를 하게 되는 것은 update뿐만 아니라 delete에도 동일하게 작동한다.
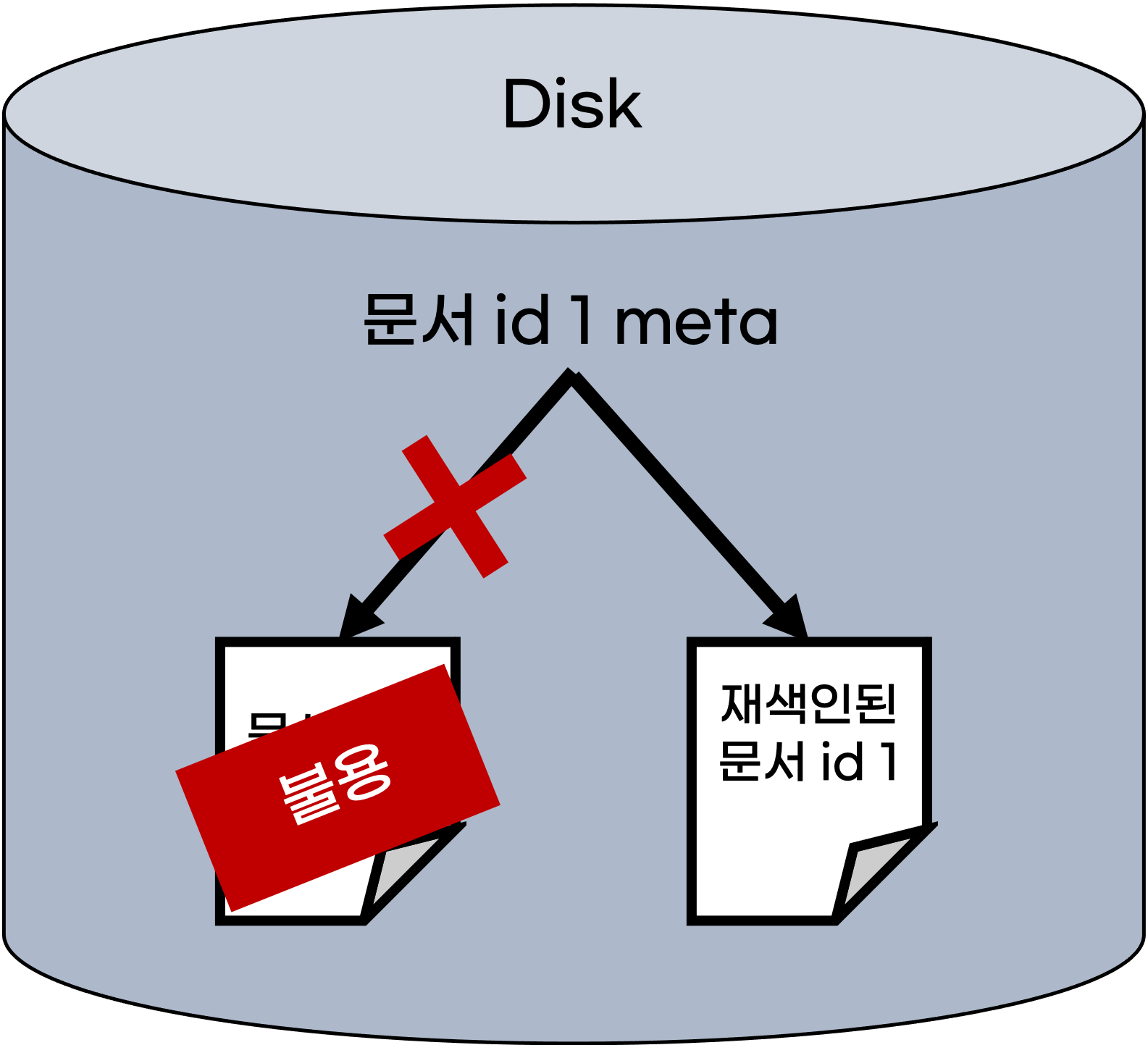
물리적 디스크에 쓰고 지우는 비용이 큰 연산을 줄이기 위해
실제로 삭제하는 것이 아닌, 불용 처리를 하지만 이럴 경우 필요한 저장 공간이 계속 증가하게 되고
검색 성능 또한 낮아지는 문제점이 발생한다.
검색 성능이 낮아지는 이유는 간단히 말해 검색 시 접근해야 하는 데이터의 종류가 많아지기 때문이라고 할 수 있다.
(실제로 삭제를 하지 않고, 계속 남아있기 때문)
그리고 이런 문제를 방지하기 위해 세그먼트 병합 과정이 존재하고
이를 통해 위의 문제점들을 해결하게 된다.

세그먼트 병합 과정은 크게 4 단계로 나누어 볼 수 있다.
먼저 가장 기본적으로 데이터가 물리적으로 저장되어 있는 단계에서 시작한다.
그리고 그중 색인 3을 삭제할 경우 실제 삭제를 하지 않고, 단순히 삭제 플래그 (불용 처리)를 하게 된다.
여기까지는 앞서 나온 내용과 동일하다.
이다음으로 새로운 색인이 저장되는 경우 백그라운드에서는 기존에 존재하는 색인들에 대해 병합 연산이 발생하게 된다.
그리고 이때 실제로 삭제 연산이 발생하게 되는데 불용 처리가 되어있지 않은 1,2번 색인이 병합되고 불용 처리된 3번 색인은 삭제되는 것이다.
이런 과정을 거쳐 최종적으로 4개의 색인이 2개로 감소하는 병합 과정이 발생되고 검색 성능과 저장 공간을 절약하게 된다.
결론
오늘의 내용을 요약하면
인덱스 - ES에서 단일 데이터 단위인 "도큐먼트"의 집합을 의미
샤드 - 인덱스가 각 데이터 노드에 저장될 때 분리되는 단위
세그먼트 - 샤드의 데이터가 실제로 저장되는 물리적 파일
로 정리할 수 있다.
마무리..
드디어 오랫동안 못 쓴,,, 엘라스틱서치 기본 구성 요소들에 대한 글이 마무리되었다..
앞으로는 엘라스틱 카테고리도 더 열심히 작성하는 걸로,,,,
※이 포스팅은 7.13 버전 기반으로 작성되었으며, 참고한 공식 Document 또한 동일 버전입니다.
※ 참고 자료 : https://www.elastic.co/guide/en/elasticsearch/reference/7.13/index.html
※ 참고 서적 : 기초부터 다지는 ElasticSearch 운영 노하우 - 박상헌, 강진우
'Data Engineering' 카테고리의 다른 글
| MongoDB 훑어보기 1(개요) (0) | 2022.05.31 |
|---|---|
| Grafana Migration (sqlite3 to MySQL) (1) | 2022.05.27 |
| 맥에서 하둡 설치하기 (1) | 2021.11.15 |
| 2.1.2 엘라스틱 서치의 구성 요소 및 구조 (노드) (0) | 2021.11.02 |
| 키바나 Map 활용 - 서울시 지하철 위치 데이터 (Index template) (0) | 2021.10.20 |